Introduction
All review processes require a standard to review against; and if our primary goal is to catch bugs and ensure our code is doing the tasks intended, we need to lay out just what those tasks are. By answering the question 'what are we trying to achieve?', we set a finite limit on what should and should not be included in our project; this is called defining a scope, and it gives us a critical frame of reference for judging new contributions. Many a coding project has failed due to 'feature creep' - the phenomenon of endlessly adding just one more interesting idea to the code, regardless of original intentions. Make no mistake: there is an infinite number of interesting ideas in the world. Trying to roll them all up into one project results in a monstrously huge codebase that is impossible to understand, maintain or use.
Once we have that high-level statement of what we're trying to achieve, we can begin to sketch out a rough plan for our code - where do we want to start from, and what are the steps we expect to have to go through to get to our goal? At this stage, we aren't trying to lay out every single implementation detail; rather, we want a roadmap that lets us do two things:
- Separate and simplify the steps to achieving our goals. After sketching a first draft of a plan, points at which to divide a problem up often become obvious: these are extremely valuable opportunities! By taking advantage of opportunities to split a problem up, we turn a complicated analysis into a series of simpler tasks - and the smaller and simpler each of these tasks are, the more likely you'll be able to catch bugs in them as you examine and use the code. Furthermore, as tasks are split up, they tend to become more generic, and a piece of code that accomplishes a more generic goal is more likely to be able to be reused in the future. This is the practice of writing modular code: code that is built out of many small, simple pieces, that are easy to debug and easy to use.
- Communicate our goals to our collaborators. A relatively simple, high-level roadmap is a valuable tool for helping our colleagues understand how to use and contribute to our software. Consider the following problem: a newcomer wants to participate in your project. What's the best possible understanding of the project we can give her within five minutes of her arrival? This is a 'five minute plan' - a clear, high-level roadmap that can orient a collaborator quickly, so they can begin to make useful contributions as soon as possible.
So, our two goals at this stage are:
- Define the scope of our project, so we can make judgements on what should and shouldn't be included; answer the question, 'what are we trying to achieve?'
- Sketch a high-level plan of our project, so we can split it up into simple tasks and communicate the lay of the land to collaborators quickly and easily; this 'five minute plan' should be digestible by a newcomer inside of five minutes.
Example
A bacteriophage ('phage' for short) is a virus that infects bacteria. In order to stave off these infections, bacteria keep chunks of phage genome in their own DNA, to serve as templates to help them recognize phages when they attack. An interesting study in immunology, then, would be to examine and compare repositories of phage and bacteria DNA to see where exactly these chunks of phage genome appear in bacterial DNA, so we can understand better this genetic archival process (just such a project can be found here).
Sounds like a job for some code! We can immediately write down a simple goal for this project:
"Download phage and bacteria genomes from open databases, and identify the nature and position of matches to phage DNA within bacteria DNA."By writing down a simple statement that circumscribes the scope of our project, we have done ourselves a great service: now, when an eager colleague comes along who is interested in something similar but not quite the same, and suggests we add functionality to look for instances of horizontal gene transfer between bacteria, we can easily judge that this would be out of scope, point to our goals, and say politely but resolutely, 'no'. Would code to identify horizontal gene transfer be interesting and useful? Absolutely! But the mistake we are trying to avoid is rolling up too much complication into one project. By keeping things focused and simple, maintaining and using our code remains fast and easy, and bugs remain easier to catch. That horizontal gene transfer idea is an excellent project in its own right - it deserves to stand on its own, in its own easily maintained project. To help everyone understand the scope of your project, include this statement in the documentation - somewhere prominent, like the top of the README file.
Now that we know what we're trying to accomplish, we can start to imagine some simple steps to get there. An enormously useful tool in this process is a simple flow chart. We can turn our original statement into a simple flow chart as follows:
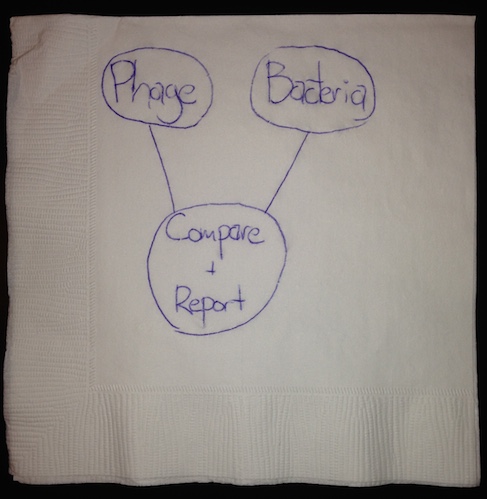
Once we've drawn even this simple diagram, we can start to think more clearly about our project. Consider, for example, the 'compare and report' step - what does this mean? What will be involved in achieving this? Perhaps the place we're getting our data from reports it in some messy or awkward manner; we'll have to tidy it up into a form more useful for our purposes. Then, we want to search for matches between phage and bacteria DNA, and report those matches; the 'compare and report bubble' breaks down into something of the form:
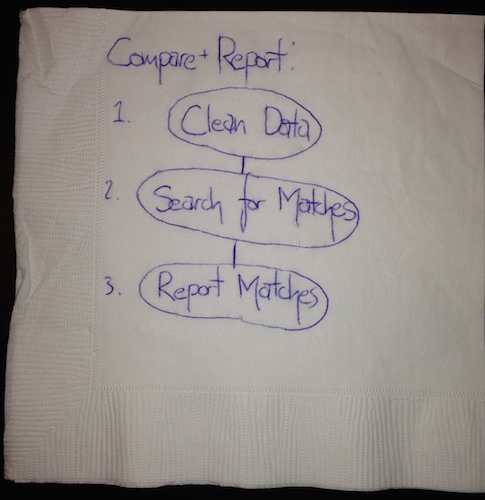
Now, some more questions arise: will the cleaning process be the same for the phage and bacteria raw data? Probably we should consider splitting these up into separate cleaning processes for each type. And how exactly do we intend to do that 'search for matches' step - searching through data can be complicated, but we can simplify the process by using a database with built-in search functionality. Our flow chart becomes something like:
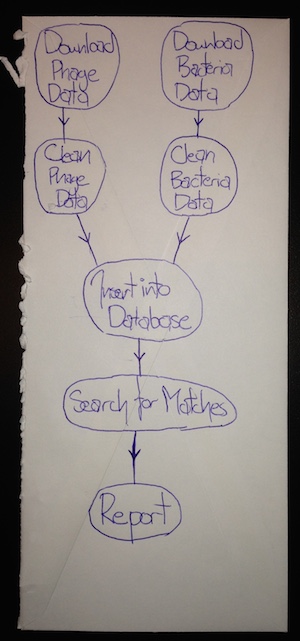
At this point, something very powerful has occurred; we've split the process up enough, that a major logical division has emerged:
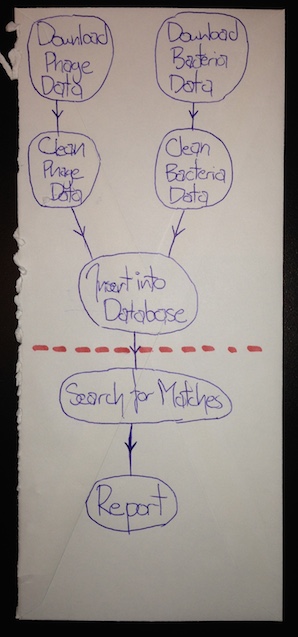
Once that database is populated, we can carry on with our phage / bacteria DNA matching search. But we've also created a useful artifact (the database) that can be reused for other tasks in the future - for example, we can tell that keen colleague that while we aren't going to write horizontal gene transfer detection algorithms into our project, she's welcome to use our database as a starting point to do it herself. What's more, we've created a logical division of labor in our own project; one grad student can work on getting the data downloaded, cleaned up and populated in the database, while another completely independently figures out how to search for matches and report the results. By splitting tasks up, we've made them simpler, easier to reuse, and easier to implement. And when we get down to the business of reviewing code, we've set ourselves up to answer much simpler questions; deciding if a piece of code is doing one simple bubble in our flow chart is much easier than deciding if it's contributing to the whole project in some poorly defined sense. Finally, this flow chart is a great example of a 'five minute plan' - a new collaborator can look at it, and quickly grasp the basic idea of what's going on.
Don't Overdo It (The Plan Will Change)
Having a clear plan is hugely helpful in communicating with collaborators, keeping projects well-managed, and setting the task of code review up to be fast and easy. But don't overdo it. The reality of most software projects is that needs and goals are emergent - they become clearer as the project progresses, and this is especially true when you throw scientific discovery into the mix. Planning every last detail of a project up front is called waterfall design, and while it seems like it would be a logical extension of planning to make sure that plan is as detailed and complete as possible, it usually backfires. An exquisitely detailed plan written up-front almost never predicts all the problems and discoveries that emerge during the development process; and then to change such a detailed document to reflect these emergent details is a huge amount of work, which people rarely make time for in practice. The result is a project plan that is out of sync with the realities of the project, that ends up misleading and confusing newcomers, and misrepresenting the project as a whole.
Therefore, keep this plan simple and high-level, so that it can be changed easily (do not, however, let people bully you into changing the plan without due cause - remember, part of the point of this step is to help you judge what does and does not belong in this project; but that filter should be your deciding authority, justified and communicated by the plan, not the cumbersome nature of an overly-detailed strategy document). A good guiding principle is to answer the question: 'what is the best introduction to this project I can give a newcomer in five minutes?'
Summary
In order to set up the process of code review and enable effective collaboration, start by writing down answers to two questions:
- What is the overall goal of this project? This gives you a mission statement that helps control the scope of the project, and make judgements on what to include.
- What is the 'five-minute plan' for this project? Sketch out a plan for how this project is going to achieve its goals, possibly as a flow chart, that can be communicated to a new collaborator in under five minutes; look for opportunities to split tasks up into simple, independent chunks.
Next Lesson
In Defining Good Contributions, we'll learn how to create a set of ground rules for contributions, that will raise the quality of code submitted and make the review process faster and simpler.